

En tant que développeur de package, on prête une attention particulière à nos fonctions maisons, à leur documentation et à leurs tests unitaires. Pour rendre l’expérience utilisateur encore plus complète, il peut être utile d’y incorporer des données. On vous explique tout ici !
Si vous n’êtes pas familier de l’implémentation des tests unitaires, nous vous conseillons de lire notre article sur le sujet : https://rtask.thinkr.fr/fr/attentes-verifiees-plongez-dans-lunivers-des-tests-unitaires-avec-expect_/
J’ai pas le temps de lire : de quoi ca parle ?
Table des matières
Dans cet article, nous présentons les différentes manières d’incorporer des données dans un package R. Nous présentons les trois dossiers permettant de stocker des données et comment y accéder, que l’on soit utilisateur du package ou développeur. Enfin, nous présentons les bonnes pratiques pour les documenter.
Pourquoi inclure des données dans un package ?
Dans un package il peut être utile d’incorporer des données pour plusieurs raisons :
- Faciliter l’utilisation du package : les données incluses dans le package sont directement accessibles par les utilisateurs.
- Faciliter la reproductibilité : les données incluses dans le package permettent de reproduire les exemples fournis dans la documentation.
- Faciliter les tests unitaires : les données incluses dans le package peuvent être utilisées pour tester les fonctions du package.
- Diffuser de l’information : partager des éléments de documentation, des articles scientifiques, des échantillons de code …
On voit ici que « données » doit être interprété au sens large. Il va concerner des données tabulaires telles qu’on aura l’habitude de les manipuler dans R (sous forme de fichiers csv ou xlsx, ou encore d’objets R data.frame) mais également des images, des fichiers de configuration, des articles, des exemples de code, etc.
Les répertoires de données dans un package
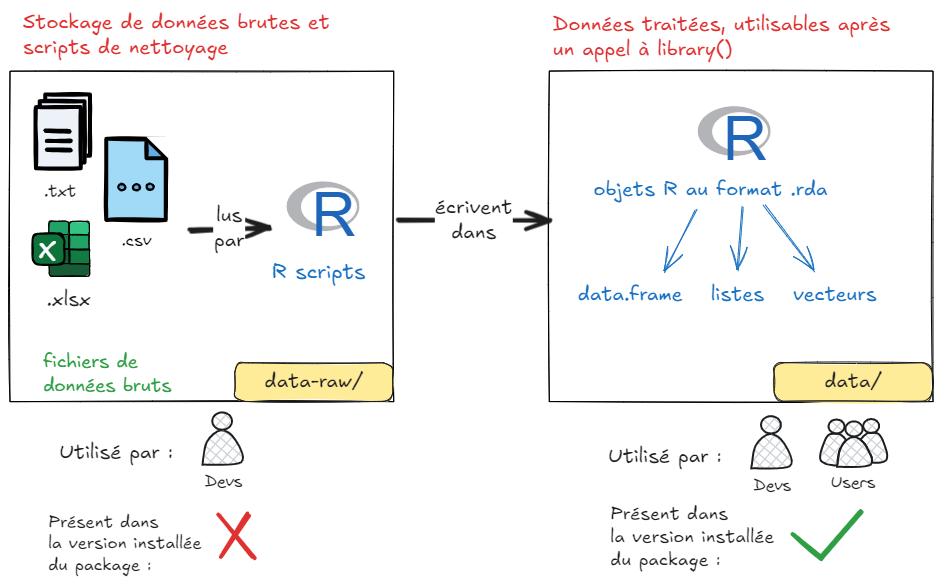
Il existe trois répertoires dans un package R qui permettent de stocker des données, data-raw/, data/ et inst/, chacun ayant une utilité spécifique et étant utilisable par une population spécifique (développeurs VS utilisateurs).
Le binome data-raw/ et data/
L’objectif ici est de mettre à disposition des utilisateurs du package des données qui seront utilisées par les fonctions du package ou présentées dans les exemples de la documentation. Il s’agira de données représentées sous forme d’objets R (data.frame, list, etc.).
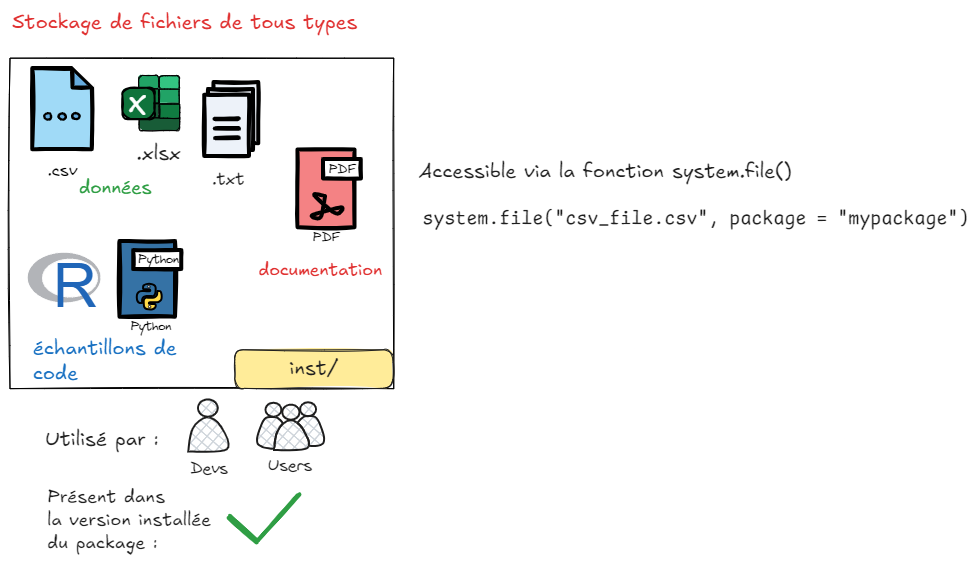
Le répertoire inst/
Ce répertoire permet de stocker des fichiers sans contrainte de format : fichier tabulaire, exemple de scripts de code, notebook au format rmd/qmd, documentation pdf … Il n’y a pas de limite.
Utiliser data-raw/ + data/
Cas d’usage : on souhaite mettre à disposition des utilisateurs du package des données qui seront utilisées par les fonctions du package. L’objectif est de pouvoir de manière native y accéder depuis les fonctions du package. Vous avez surement l’habitude d’utiliser des data.frame préchargés dans R comme mtcars ou iris, c’est exactement le même principe.
data-raw/
Le dossier data-raw/ est utilisé pour stocker les scripts de préparation des données. Les fichiers de ce dossier ne sont pas inclus dans le package final installé sur l’ordinateur d’un utilisateur, mais ils contiennent le code nécessaire pour générer les jeux de données qui seront ensuite inclus dans le package.
data/
Une fois préparées dans data-raw/, les données sont stockées dans le dossier data/. Les fichiers de ce dossier sont inclus dans le package final et sont accessibles par les utilisateurs du package. Les fichiers sont stockés au format .rda et sont chargés dès lors qu’un utilisateur lance library(monpackage).
Exemple
1 – Création du dossier data-raw/ avec la commande usethis::use_data_raw("my_dataset_demo"). Cette commande crée un fichier my_dataset_demo.R dans le dossier data-raw/
2 – Préparation du jeu de données dans le fichier my_dataset_demo.R
# Créons un échantillon du jeu de données "starwars", présent dans le package dplyr
# Voir https://github.com/tidyverse/dplyr/tree/main/data-raw et https://github.com/tidyverse/dplyr/tree/main/data
library(dplyr)
library(readr)
starwars_raw <- read_csv("data-raw/starwars.csv")
starwars_sample <- starwars_raw |>
sample_n(size = 10)
usethis::use_data(starwars_sample, overwrite = TRUE)
3 – Une fois la commande usethis::use_data(starwars_sample, overwrite = TRUE) lancée, vous verrez apparaître un fichier starwars_sample.rda dans le dossier data/.
4 – Nous avons encore un peu de travail, il nous faut maintenant documenter notre jeu de données. Pour cela, nous allons utiliser le package {checkhelper}.
checkhelper::use_data_doc("starwars_sample")
Ceci crée un fichier doc_starwars_sample.R dans le dossier R/ du package. Ce fichier contient la documentation du jeu de données. Vous pouvez maintenant éditer ce fichier pour ajouter des informations supplémentaires sur le jeu de données.
#' starwars_sample
#'
#' Description.
#'
#' @format A data frame with 10 rows and 14 variables:
#' \describe{
#' \item{ name }{ le nom du personnage }
#' \item{ height }{ numeric }
#' \item{ mass }{ numeric }
#' \item{ hair_color }{ character }
#' \item{ skin_color }{ character }
#' \item{ eye_color }{ character }
#' \item{ birth_year }{ numeric }
#' \item{ sex }{ character }
#' \item{ gender }{ character }
#' \item{ homeworld }{ character }
#' \item{ species }{ character }
#' \item{ films }{ character }
#' \item{ vehicles }{ character }
#' \item{ starships }{ character }
#' }
#' @source Source
"starwars_sample"
Si la structure globale du fichier doit être conservée, nous pouvons si nécessaire éditer les informations de description, de format et de source.
Enfin il nous reste à générer la documentation au format Latex en utilisant la commande devtools::document() ou attachment::att_amend_desc().
Une fois votre package installé (avec remotes::install_local()) et chargé, vous pourrez accéder à votre jeu de données en utilisant la commande data("starwars_sample").
Utiliser inst/
Cas d’usage : on souhaite stocker des fichiers voués à être utilisés uniquement dans des tests unitaires, ou on souhaite partager des éléments de documentation supplémentaires (ex: article scientifique).
Exemple
1 – on crée le dossier inst/ à la racine du package : dir.create(here::here("inst")).
2 – on dépose les fichiers souhaités.
3 – on installe le package remotes::install_local().
4 – les fichiers sont maintenant accessibles avec une fonction un peu particulière : system.file(), qui va pointer à la racine de inst/. Par exemple, pour accéder à un fichier article.pdf dans le dossier inst/, on utilisera la commande system.file("article.pdf", package = "monpackage"). Si ce même article est dans un sous-dossier appelé « doc », on utilisera system.file("doc", "article.pdf", package = "monpackage").
Attention : system.file() ne fait pas de lecture d’un fichier, il renvoie seulement le chemin d’accès
Conclusion
Vous savez maintenant tout sur l’incorporation de données dans un package R. Vous avez appris à stocker des données dans les dossiers data-raw/, data/ et inst/, et à les rendre accessibles depuis les fonctions du package. Vous avez également appris à documenter ces données pour les rendre utilisables par les utilisateurs du package.
Que ces éléments soient à destination des utilisateurs ou des développeurs, vous avez maintenant toutes les clés en main pour enrichir votre package R avec des données.
Pour aller plus loin
Pour ceux qui souhaitent aller plus loin et maîtriser l’art de créer des packages robustes, incluant des données, jetez un coup d’oeil sur notre formation – R Niveau 2 – Développeur – Création de packages



