

Certaines personnes se sont récemment exprimées au sujet des mauvais usages de la "stratégie du petit r", un mécanisme de partage de données entre modules {shiny} qui a été détaillé à la fois dans le livre Engineering Production-Grade Shiny Apps et dans un ancien billet publié en 2019 sur ce blog. Et oui, si vous vous posez la question, je me suis senti vieux en réalisant que ce billet a presque 7 ans maintenant 😅
Je suis toujours ravi qu’on me prouve que j’ai tort, de remettre en question ma manière de construire des logiciels et de devenir un meilleur ingénieur logiciel. Mais comme personne ne nous a contactés pour discuter des idées derrière cette stratégie, j’ai pensé que c’était le moment idéal pour vous faire un point sur les approches les plus récentes que j’utilise pour partager des données entre modules {shiny}, avec quelques réflexions et commentaires sur la "stratégie du petit r".
Découvrir les modules {shiny}
Je construis des applications {shiny} depuis un bon moment. J’en ai probablement développé plus que je ne peux en compter, et pendant bien plus longtemps que je n’ose l’admettre. L’une des applications dont je suis le plus fier est utilisée par plus de 1 000 personnes dans une grande entreprise et gère des millions d’euros chaque année. Je travaille dessus depuis cinq ans (ouch).
Je me souviens encore du jour où Vincent nous a envoyé un message sur Slack, en partageant une vidéo sur les modules {shiny} et en expliquant comment ils allaient changer notre façon de développer des applis. J’étais dans un train, de retour d’une des nombreuses conférences R auxquelles j’ai assisté (et où j’ai pris la parole) au fil des années — je crois que c’était en 2017, mais je n’en suis pas vraiment sûr. Et je l’avoue : je n’avais absolument aucune idée de ce dont parlait cette vidéo, ni de la manière dont ça pourrait s’intégrer à mes applications {shiny} de l’époque.
Comme le geek que je suis, j’ai regardé cette vidéo plusieurs fois parce que je voulais la comprendre et l’utiliser. Chaque fois que Vincent arrive en disant que quelque chose va changer votre style de code, vous avez intérêt à écouter et à comprendre. Il m’a fallu un peu de temps, mais après quelques mois, les modules {shiny} étaient devenus un élément central de mon workflow de développement, et la fonction add_module() de {golem} est devenue l’une de mes préférées : elle m’a fait gagner cinq minutes de copier-coller périlleux à chaque fois que j’ai besoin d’un nouveau module. C’est une quantité non négligeable de temps de vie économisé grâce à une simple fonction.
Mais l’une des choses les plus complexes avec les modules {shiny}, c’est ceci : comment partager un état global, des données et de la réactivité entre eux ? Comment accéder au CSV lu dans mod_csv_reader depuis mod_data_visualisation ?
Plongeons dans cette question.
Qu’est-ce qu’un module {shiny} ?
Les modules sont des fonctions
J’ai l’impression que les modules {shiny} ont été présentés à tort comme des « morceaux de code {shiny} réutilisables ». Alors oui, ils le sont, mais 95 % des modules que j’ai écrits dans ma carrière n’ont été utilisés qu’une seule fois. Et c’est parce que, la plupart du temps, les morceaux d’une application sont trop spécifiques pour être réutilisés ailleurs.
Les modules {shiny} sont donc surtout utiles parce qu’ils répondent à un problème de portée (scoping) : via deux fonctions, ils vous permettent de définir une petite partie de votre application sans avoir à vous soucier de l’unicité des identifiants à l’échelle de toute l’application. En gros, ce sont des briques : vous partez du niveau supérieur, puis vous découpez en éléments de plus en plus petits.
Le fait que les modules {shiny} soient des fonctions implique plusieurs choses :
- Ils opèrent dans un écosystème d’environnements
- Ils sont scopés : ce qui s’y passe y reste en général, sauf si vous décidez activement du contraire
- Ils peuvent prendre des entrées et produire des sorties
Les bonnes pratiques d’ingénierie logicielle nous disent : une fonction doit prendre un ensemble d’entrées, faire une seule chose, et produire une sortie — et on emboîte ces fonctions les unes dans les autres comme des poupées russes pour construire un workflow plus large. On peut donc avoir, par exemple, un module qui contient un onglet de l’application, qui contient deux cartes, dont une carte est un module qui contient un module avec un fileInput pour lire un CSV.
Jetons un œil à une application simple comme ce GPX Viewer, dont le code source est disponible ici : https://github.com/ThinkR-open/gpxviewer.
Cette application suit un workflow Shiny assez courant : prendre un jeu de données, le tracer, puis le résumer. Il existe plusieurs manières de découper cette application en modules.
On peut voir cela comme un découpage des modules par « faire une seule chose » (configuration des données / visualisation des données) :
Une autre possibilité : (téléverser / configurer / tracer / résumer) :
Ou encore (vérifier un exemple / téléverser / configurer / télécharger / tracer / résumer) :
Ce que j’essaie de montrer, c’est que « faire une seule chose » peut être relatif dans le contexte d’une grosse application. Surtout, et je pense que c’est le point principal : il faut trouver un équilibre entre le parfait et le pratique. Par exemple, je travaille actuellement pour un client dont la base de code (R uniquement) fait un peu moins de 20 000 lignes, et si vous partez du niveau supérieur, le module le plus profond dans la pile se trouve six niveaux plus bas. Bien sûr, certains modules pourraient être découpés en plus petits, puis en plus petits encore, etc.
Mais j’essaie de garder les choses faciles à maintenir. Au vu de la taille actuelle de la base de code, ajouter des couches supplémentaires ou aller plus profond rendrait le code bien plus complexe et plus difficile à maintenir, sans bénéfice réel. Donc oui, certains modules ne sont pas parfaits, et ils ne font peut-être pas « une seule chose ».
Comme on dit : « le mieux est l’ennemi du bien ».
Les fonctions peuvent-elles prendre des listes comme paramètres ?
J’ai eu un débat interne sur ce point pendant bien trop longtemps. Une fonction ne peut-elle prendre que des paramètres scalaires, ou ces paramètres peuvent-ils aussi être des listes ?
J’ai fini par accepter cette idée pour deux raisons :
- Les data frames sont des listes, et je ne vois pas de bonne raison d’interdire de passer une
data.framecomme argument à une fonction. - JavaScript est rempli de fonctions qui prennent des valeurs scalaires et une liste de paramètres, et ça fonctionne très bien.
Par exemple, faire une requête HTTP en JS ressemble à ceci :
fetch(
"/api/users",
{
method: "GET",
headers: {
"Content-Type": "application/json",
"Accept": "application/json",
"Authorization": "Bearer YOUR_TOKEN",
}
}
)
Devinez quoi : dans {httr} (je sais, je suis old-school), vous feriez :
GET(
url = "/api/users",
config = add_headers(
`Content-Type` = "application/json",
`Accept` = "application/json",
Authorization = "Bearer YOUR_TOKEN"
)
)
Oui, config est une list().
Si vous avez l’impression que je m’éloigne un peu de mon point de départ, vous avez raison… un peu. Mais c’est pertinent pour ce que je vais expliquer dans la suite de ce billet.
Partager des données entre modules
De quoi parle-t-on exactement ?
Imaginons, un instant, l’architecture Shiny suivante, qui est, honnêtement, très simple (la plupart du temps, les modules ne seront pas découpés aussi uniformément).
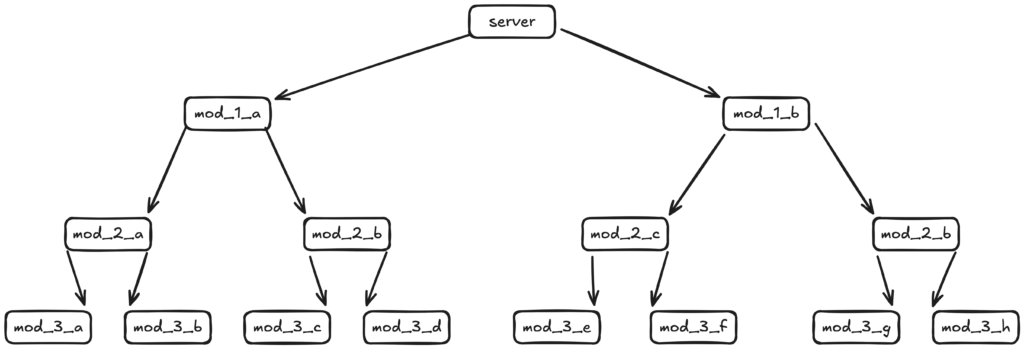
En général, les modules vivent dans deux scopes :
- Ils font des choses en interne
- Ils font des choses qui doivent être transmises à d’autres modules
Faire des choses en interne est assez standard et ne demande pas beaucoup de réflexion (tant que vous n’oubliez pas le ns() 😅), mais partager des éléments d’un module à l’autre dans un contexte réactif peut être plus difficile. Par exemple, disons que notre application contient ceci : mod_3_a a une case à cocher, mod_3_b a un module de téléversement de données, mod_3_c a un ensemble d’options de configuration pour nettoyer les données, mod_3_d a un ensemble d’options de configuration pour le graphique, et enfin mod_3_g est le module qui trace le graphique. Une fois les données téléversées et nettoyées, le code doit être organisé de façon à permettre deux choses :
- Le jeu de données et la configuration sont disponibles dans
mod_3_g - Le contexte de
mod_3_gest invalidé et un nouveau graphique est dessiné (c.-à-d. que la réactivité est déclenchée)
Si on n’avait que (1), ce serait un peu plus simple, mais il faut aussi rendre l’ensemble réactif.
Explorons maintenant les patterns possibles.
Passer des objets réactifs
Une chose que j’ai apprise au fil des années, c’est que ce qui fonctionne pour des applications d’exemple peut devenir un cauchemar en production. La documentation officielle Shiny recommande le pattern suivant : retourner un ou plusieurs objets reactive() qui peuvent être passés à d’autres modules.
Ici, dans notre contexte, cela voudrait dire le code suivant (en allant du bas gauche de l’arbre vers le bas droite) :
# Bottom left level
mod_3a_server(){
return(reactive({ input$abc }))
}
mod_3b_server(){
return(reactive({ input$def }))
}
mod_3c_server(){
return(reactive({ input$ghi }))
}
mod_3d_server(){
return(reactive({ input$jkl }))
}
mod_2_a(){
mod_3a_reactive <- mod_3a_server()
mod_3b_reactive <- mod_3b_server()
return(
list(
mod_3a_reactive = mod_3a_reactive,
mod_3b_reactive = mod_3b_reactive
)
)
}
mod_2_b(){
mod_3c_reactive <- mod_3c_server()
mod_3d_reactive <- mod_3d_server()
return(
list(
mod_3c_reactive = mod_3_c(),
mod_3d_reactive = mod_3d()
)
)
}
mod_1_a(){
mod_2_a_results <- mod_2_a()
mod_2_b_results <- mod_2_b()
return(
list(
mod_3a_reactive = mod_2_a_results$mod_3a_reactive,
mod_3b_reactive = mod_2_a_results$mod_3b_reactive,
mod_3c_reactive = mod_2_b_results$mod_3c_reactive,
mod_3d_reactive = mod_2_b_results$mod_3d_reactive
)
)
}
# in server
reactives_from_mod_1_a <- mod_1_a(...)
mod_1_b_server(
mod_3a_reactive = reactives_from_mod_1_a$mod_3a_reactive,
mod_3b_reactive = reactives_from_mod_1_a$mod_3b_reactive,
mod_3c_reactive = reactives_from_mod_1_a$mod_3c_reactive,
mod_3d_reactive = reactives_from_mod_1_a$mod_3d_reactive
)
# in mod_1_b
mod_1_b_server(){
mod_2_d_server(
mod_3a_reactive = mod_3a_reactive,
mod_3b_reactive = mod_3b_reactive,
mod_3c_reactive = mod_3c_reactive,
mod_3d_reactive = mod_3d_reactive
)
}
mod_2_d_server(){
mod_3g_server(
mod_3a_reactive = mod_3a_reactive,
mod_3b_reactive = mod_3b_reactive,
mod_3c_reactive = mod_3c_reactive,
mod_3d_reactive = mod_3d_reactive
)
}
mod_3g_server <- function(...){
output$xyz <- renderPlot({
draw(
mod_3a_reactive = mod_3a_reactive(),
mod_3b_reactive = mod_3b_reactive(),
mod_3c_reactive = mod_3c_reactive(),
mod_3d_reactive = mod_3d_reactive()
)
})
}
Si vous avez l’impression que c’est un bazar et que c’est difficile à raisonner, c’est parce que ça l’est. Et on est dans un cas simple où les données circulent à la même profondeur dans la pile.
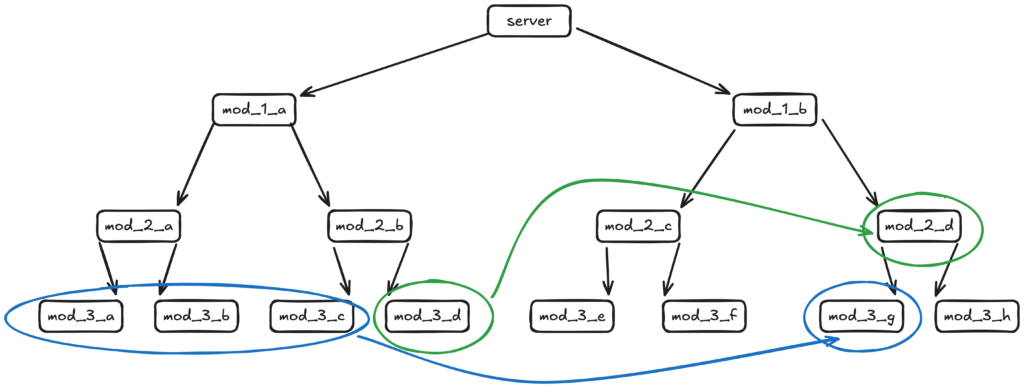
Avec ça, on obtiendrait :
mod_1_b_server(){
mod_2_d_server(
mod_3a_reactive = mod_3a_reactive,
mod_3b_reactive = mod_3b_reactive,
mod_3c_reactive = mod_3c_reactive,
mod_3d_reactive = mod_3d_reactive
)
}
mod_2_d_server(){
output$abc <- renderText({
mod_3d_reactive()
})
mod_3g_server(
mod_3a_reactive = mod_3a_reactive,
mod_3b_reactive = mod_3b_reactive,
mod_3c_reactive = mod_3c_reactive
)
}
mod_3g_server(){
output$xyz <- renderPlot({
draw(
mod_3a_reactive = mod_3a_reactive(),
mod_3b_reactive = mod_3b_reactive(),
mod_3c_reactive = mod_3c_reactive()
)
})
}
Et tout ça juste pour faire voyager quatre valeurs à travers le graphe — dans un stack assez peu profond et organisé de façon uniforme, comme je le disais. Et c’est parce qu’on ne fait que passer des réactifs comme paramètres.
mod_3g_server <- function(
dataset,
mod_3a_reactive,
mod_3b_reactive,
mod_3c_reactive,
with_coordflip = TRUE
){
output$xyz <- renderPlot({
draw(
dataset = dataset,
mod_3a_reactive = mod_3a_reactive(),
mod_3b_reactive = mod_3b_reactive(),
mod_3c_reactive = mod_3c_reactive(),
with_coordflip = with_coordflip
)
})
}
C’est encore plus complexe si vous ajoutez une couche de reactive() à l’intérieur de votre module :
mod_3g_server <- function(
dataset,
mod_3a_reactive,
mod_3b_reactive,
mod_3c_reactive,
with_coordflip = TRUE
){
the_plot_to_draw <- reactive({
drawing <- draw(
dataset = dataset,
mod_3a_reactive = mod_3a_reactive(),
mod_3b_reactive = mod_3b_reactive(),
mod_3c_reactive = mod_3c_reactive(),
with_coordflip = with_coordflip
)
return(drawing)
})
output$xyz <- renderPlot({
the_plot_to_draw()
})
}
Bon courage pour comprendre le graphe réactif de celui-là.
En aparté, je trouve les objets reactive() conceptuellement élégants, mais je ne pense pas qu’ils devraient être la brique de base. Regardons rapidement :
the_data_frame <- reactive({
result <- clean_and_transform(
input$dataset
)
return(result)
})
output$table_one <- renderDT({
the_data_frame()
})
C’est effectivement propre : chaque fois que input$dataset change, quelque chose est calculé et affiché. Ça marche bien pour de petits exemples, mais dès que vous devez le passer à d’autres fonctions ou modules, ça devient plus difficile à raisonner, surtout si vous n’avez pas l’habitude de manipuler des fonctions comme des objets.
J’ai rencontré beaucoup de développeurs R qui ne savaient pas qu’on pouvait passer une fonction en paramètre à une autre fonction, et la plupart du temps, avec reactive(), les gens copient des exemples trouvés sur le web sans vraiment comprendre ce qui se passe.
Mais comment font-ils dans d’autres langages ?
Je n’ai pas développé de « vraies » applications dans tant de langages que ça, mais il y en a un que je connais (plus ou moins) bien : JavaScript.
À l’été 2024, nous avons passé quelques semaines à travailler sur Rlinguo, une application mobile capable d’exécuter du code R. Elle est construite en React et fonctionne comme {shiny} (enfin, d’un point de vue conceptuel) : vous avez des objets avec état, et quand ces objets changent, ils déclenchent le recalcul d’une autre partie de l’application. Dans notre cas, chaque interaction avec le premier onglet met à jour le second onglet (celui de la visualisation).
Dans l’application, la première couche crée une instance webR, une connexion SQLite et un objet score, utilisé pour déclencher le recalcul de la visualisation. Au lancement, un écran de chargement attend que webR soit prêt. Une fois que c’est le cas, webR est interrogé pour des fonctions, et une fois votre réponse validée (dans le « module » 1), une alerte est envoyée à la visualisation (dans le « module » 2) pour interroger la base SQLite et recalculer le graphe.
En résumé, certains objets sont créés au niveau supérieur et servent à partager des données et à déclencher la réactivité d’un « module » à l’autre.
Note : mon collègue Arthur a mentionné que Vue.js a quelque chose qui s’appelle un store dans Pinia. Je ne sais pas exactement comment ça fonctionne, mais apparemment c’est plus ou moins la même chose que les reactiveValues. Et Claude l’a confirmé 😄
La “stratégie du petit r”
Une stratégie que nous recommandions est ce que nous avons appelé la « stratégie du petit r ». Avec le recul, je peux admettre que c’était un mauvais choix de nom, mais bon… shit happens.
Le principe est assez simple : au lieu de retourner et de passer des objets reactive() comme arguments, vous créez un ou plusieurs reactiveValues() à un niveau supérieur, que vous passez ensuite vers le bas aux modules de niveau inférieur. Les reactiveValues() se comportent beaucoup comme des environnements : des valeurs définies plus bas dans la pile deviennent disponibles partout.
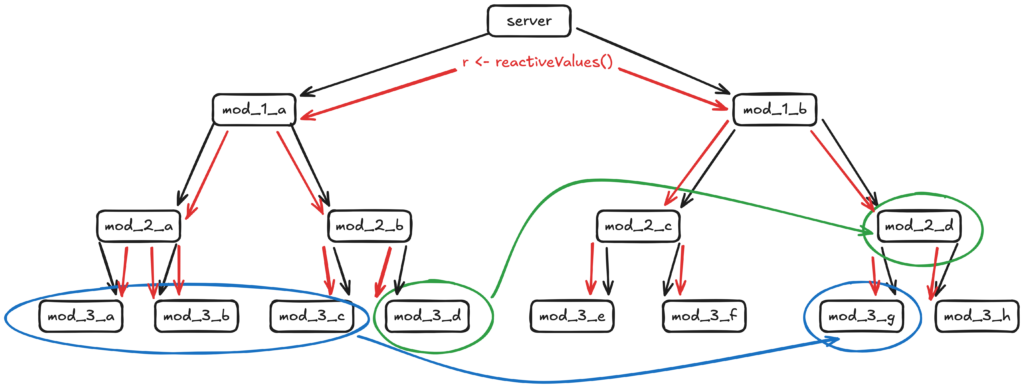
Je pense toujours que c’est une manière valide de partager des données, mais seulement si vous évitez de l’appliquer trop littéralement et que vous vous concentrez sur sa mise en œuvre concrète.
La principale critique que j’ai lue à propos de cette approche est qu’on finit avec un énorme objet r contenant 300 entrées, un monstre impossible à déboguer.
Oui, ces monstres existent. Mais je ne pense pas que l’idée en elle-même soit le problème — il est toujours plus facile d’accuser l’outil que de reconnaître le manque de compréhension derrière sa mauvaise utilisation. Ou, comme l’a écrit Beckett : « Voilà l’homme tout entier, s’en prenant à sa chaussure alors que c’est son pied le coupable. »
Voici quelques réflexions en vrac :
1. Ne l’appelez pas r (probablement)
Les conventions sont précieuses : elles aident les humains à s’y retrouver. Je pense qu’on en a besoin quand on développe des logiciels : on passe plus de temps à lire qu’à écrire du code, et les conventions aident à naviguer dans une codebase inconnue. Par exemple, je sais que tous les fichiers qui commencent par mod_ dans {golem} contiennent des modules.
Quand nous présentions des exemples pour la « stratégie du petit r », nous utilisions r <- reactiveValues(). Mais c’était uniquement pour l’exemple. Dans ce billet, j’ai utilisé mod_1_a et mod_3_g. Merci de ne pas réutiliser ces noms : ce ne sont que des exemples.
Donc oui, un petit r peut être déroutant si vous ne travaillez pas avec des personnes qui connaissent cette convention. Si je tombe sur une base de code avec un r, je saurai ce que c’est parce que je l’ai déjà utilisé. Mais aujourd’hui, j’ai tendance à préférer des noms plus explicites, généralement global (puisque c’est un stockage global) ou simplement storage. Vous préférerez peut-être des noms comme global_storage, reactive_storage, ou tout autre nom plus clair pour votre équipe.
Cela dit, tout est une question de contexte et de conventions. Par exemple, dplyr::mutate() a un paramètre appelé .data. On peut discuter du choix, mais à chaque fois que je vois .data, je sais que c’est une table et qu’on est dans le tidyverse.
2. Vous n’avez pas besoin de tout partager entre tous les modules
Il y a une probabilité infime que vous ayez besoin de partager absolument tout entre tous les modules.
Pensez à l’application sur laquelle vous travaillez en ce moment. Oui, il y a probablement une poignée de choses qui doivent être disponibles partout, mais il n’y a aucune raison de tout stocker dans un reactiveValues() défini au niveau supérieur.
Vos modules doivent rester scopés, et c’est probablement l’une des idées les plus importantes pour que cette implémentation fonctionne :
- Ce qui n’est nécessaire qu’à l’intérieur d’un module ne devrait pas être stocké dans un
reactiveValues()défini plus haut - Ce qui n’est nécessaire qu’à l’intérieur d’un module ne devrait pas être passé aux modules de niveau inférieur
C’est aussi simple que ça. Voyez votre application comme un arbre : les valeurs nécessaires uniquement au niveau N ne devraient pas « remonter » au niveau N + 1.
3. Vous pouvez devez avoir plusieurs reactiveValues()
La conséquence logique du point précédent est simple : vous avez besoin de plusieurs reactiveValues(), à différentes portées dans votre application.
Voici un extrait simplifié d’un module d’une application sur laquelle je travaille actuellement :
mod_abstract_server <- function(
id,
global
) {
local <- reactiveValues()
observeEvent(
input$language,{
local$ai_alert <- build_text_for_ai_alert(
input$language
)
})
output$alert_ai <- renderUI({
local$ai_alert
})
country_rv <- reactiveValues()
observe({
country_rv$country <- input$country
})
mod_checklist_server(
"checklist_1",
country_rv = country_rv,
global = global
)
}
Ici, on a :
global, (qu’on pourrait aussi appelerr_global) qui est lereactiveValues()partagé entre tous les modules. Il contient un dataset qui peut être mis à jour via un panneau d’administration, mais doit être lu dans les autres modules. Il est passé depuisapp_server, traversemod_abstract_server, puis descend jusqu’àmod_checklist_server. Je peux citer 10 cas d’usage en contexte client où ce pattern est pertinent ; demandez-moi la prochaine fois qu’on se croise en conférence.local, (qu’on pourrait aussi appelerr_local) unreactiveValues()qui stocke des valeurs nécessaires uniquement à l’intérieur du module courant.country_rv, défini dans le module et passé àmod_checklist_server.
J’aurais pu tout stocker dans global, et ça aurait quand même fonctionné. Mais ce ne serait ni une bonne organisation, ni une bonne séparation des responsabilités.
Pour résumer
Aucune structure, aucune idée et aucun framework n’empêchera jamais quelqu’un d’écrire du mauvais code. JavaScript a longtemps été moqué comme un langage trop permissif. Puis TypeScript est arrivé et a imposé plus de structure — avec une faille : on peut contourner le système et utiliser any comme type pour tout, et ça fonctionne quand même. On peut écrire du mauvais code en TypeScript, même si le langage est censé imposer une structure. Rien ne peut vous empêcher d’écrire du mauvais code.
Oui, utiliser reactiveValues() comme objet de stockage partagé entre modules peut créer des monstres si vous ne réfléchissez pas vraiment à ce que vous faites.
Oui, dans une application où énormément de valeurs circulent, essayer de tout passer via des paramètres stricts peut créer des monstres encore plus effrayants.
Oui, c’est OK d’avoir une liste comme paramètre d’une fonction de module.
Autres patterns
Voici d’autres patterns qu’on peut utiliser dans une application {shiny} pour partager des données entre modules.
Stockage via un objet R6
Un inconvénient possible de la stratégie reactiveValues() que je viens de décrire, c’est que, justement, c’est réactif — ce qui peut mener à une réactivité incontrôlée si les choses ne sont pas correctement scopées.
Un pattern que j’ai utilisé dans une application est de combiner un objet R6 (pour stocker et traiter les données) avec le mécanisme de déclenchement de {gargoyle}. L’idée derrière {gargoyle} est simple : au lieu de s’appuyer sur le graphe réactif pour s’invalider tout seul, on initialise des flags déclenchés dans le code ; quand un flag est déclenché, le contexte où ce flag est watché est invalidé.
C’est un peu plus long à implémenter, mais on contrôle mieux ce qui se passe.
Combiné à cela, vous pouvez passer un objet R6 entre les modules, et le transformer pour stocker, traiter et servir les données.
Vous pouvez en lire davantage dans « 15.1.3 Building triggers and watchers » et « 15.1.4 Using R6 as data storage » au chapitre 15 du livre Engineering Shiny.
session$userData
À utiliser avec beaucoup de prudence, mais cela peut être très efficace si vous savez ce que vous faites (et si vous n’avez pas trop de choses à partager).
L’objet session est un environnement disponible partout dans votre application Shiny. Il représente l’interaction en cours entre chaque utilisateur et la session R (chaque utilisateur a la sienne). Cet environnement a un emplacement spécial appelé userData qui peut être rempli avec des données, et qui est scopé à la session.
La façon dont je l’ai utilisé par le passé, c’est via des wrappers, qui ressemblent à :
set_this <- function(value, session = shiny::getDefaultReactiveDomain()){
session$userData$this <- compute_this(value)
}
get_this <- function(session = shiny::getDefaultReactiveDomain()){
session$userData$this
}
Ainsi, partout où j’en ai besoin, j’utilise la fonction wrapper plutôt que session$userData$this. En général, je l’emploierais pour définir des choses au niveau supérieur qui doivent être accessibles partout en aval, mais j’ai l’impression que cela peut être un peu complexe à gérer si vous devez faire passer des données de mod_3_a à mod_3_g.
La documentation dit qu’on peut l’utiliser « to store whatever session-specific data (we) want », mais mon intuition est qu’il vaut mieux éviter d’y entasser trop de choses. Je n’ai pas de raison « rationnelle » très solide, et je serais heureux qu’on me prouve le contraire.
Un environnement dans le scope du package / au niveau supérieur de l’app
C’est quelque chose que beaucoup de développeurs R font : définir un environnement dans le namespace du package pour pouvoir y faire du CRUD une fois le package chargé. Par exemple, il y en a (plusieurs) dans {shiny} :
> shiny:::.globals
<environment: 0x10dda28a0>
La fonction shinyOptions() y écrit, et getShinyOption() y lit.
Ce pattern peut servir de stockage global, mais attention : il n’est pas scopé à la session, donc tout ce qui s’y trouve est partagé entre sessions.
Une base de données externe ou un système de stockage externe
Une autre solution consiste à stocker des valeurs dans une base externe, puis à interroger cette base depuis les modules.
Si vous essayez d’implémenter cette solution, deux points à garder en tête :
- Rendre les données spécifiques à la session, c.-à-d. utiliser
session$tokenpour identifier la session courante, et supprimer les données à la fin de la session. - Gérer la réactivité manuellement, par exemple avec
{gargoyle}.
Par exemple, avec {storr} :
# Mimicking a session
session <- shiny::MockShinySession$new()
# In module 1
st <- storr::storr_rds(here::here())
st$set("dataset", mtcars, namespace = session$token)
# In module 2
st <- storr::storr_rds(here::here())
st$get("dataset", namespace = session$token)
Bien sûr, c’est un petit extrait et il faudra plus d’ingénierie, mais vous voyez l’idée.
Conclusion
C’était un long billet, mais je voulais aller un peu plus loin dans le pourquoi, et développer les idées et les limites derrière la « stratégie du petit r ». J’aurais dû écrire ce billet bien plus tôt, mais j’imagine qu’être attaqué publiquement sur les réseaux sociaux sans avoir été consulté au préalable est une sacrée motivation.
Quoi qu’il en soit, je suis toujours partant pour discuter des idées développées ici : n’hésitez pas à commenter ou à me contacter (je suis à peu près certain que si vous en avez besoin, il est très facile de trouver un moyen de me joindre 😅).
Comme pour tout dans la vie, développer du logiciel est toujours une affaire de compromis. Chaque décision a des bénéfices et des inconvénients, et si vous n’en voyez aucun, c’est que vous n’avez pas assez creusé. En production, les codebases peuvent devenir très grandes. J’ai mentionné une application de 20 000 lignes que j’ai récemment refactorée pendant une semaine pour réduire sa taille de 20 %, mais je suis sûr que d’autres applications sur lesquelles j’ai travaillé sont encore plus grosses. Ça reste gérable si c’est bien organisé — mais ça reste complexe.
Dans un monde parfait, les modules seraient si petits qu’ils ne géreraient qu’une seule valeur, les graphes réactifs seraient entièrement sous contrôle, on aurait 100 % de couverture de tests, toutes les entrées nécessaires seraient passées en paramètres, on utiliserait un langage typé qui n’autoriserait pas les valeurs dangereuses, et aucune variable ne s’appellerait jamais x ou result.
Et puis il y a la réalité.
Le client en avait besoin hier. Son boss en avait besoin le mois dernier. Je n’ai plus de café. Et, pour être honnête, je préfère être en train de courir en forêt plutôt que de débuguer un énième renv::install().
Alors on peut prendre des raccourcis, utiliser de mauvais noms de variables, oublier de supprimer une data.frame de test de la base SQL, et créer des reactiveValues() qui deviennent des monstres.
Malgré tout, je crois sincèrement que personne n’est là pour saboter le projet.
Que tout le monde fait se son mieux au moment où il le fait avec ce qu’il a à disposition.


