

Illustration via ChatGPT.
Il y a trois choses difficiles en informatique. L’une d’elles est de faire écrire « Invalidation » correctement par ChatGPT sur une image.
Il existe un dicton qui dit : « Il n’y a que deux choses difficiles en informatique : l’invalidation du cache et le nommage des variables. » Eh bien, je dirais qu’il y en a en fait trois :
Oui, c’est une blague de nerd.
Dans cet article, nous allons explorer la programmation parallèle et asynchrone, pourquoi elle est importante pour les développeurs {shiny}, et comment vous pouvez l’implémenter dans votre prochaine application.
Parallèle vs Asynchrone
Les termes parallèle et asynchrone sont souvent utilisés de manière interchangeable lorsqu’il s’agit de « calculer quelque chose ailleurs » (par exemple, dans une autre session R). Cependant, ils décrivent des approches distinctes qui nécessitent des états d’esprit différents.
Parallèle
La programmation parallèle suit le paradigme split/apply/combine, également appelé map-reduce :
- Diviser une tâche en
nmorceaux. - Traiter chaque morceau indépendamment (souvent dans des sessions R distinctes).
- Combiner les résultats pour produire une sortie finale
En R, ce concept est illustré par la famille *apply et ses équivalents dans {purrr}. Voici un exemple simple :
lapply(
c("1", 12, NA),
\(x) {
Sys.sleep(1) # Simulate computational time
sprintf("I'm %s", x)
}
)
Ici, chaque élément est traité séquentiellement, un par un. Les tâches sont indépendantes et n’ont pas besoin de communiquer entre elles.
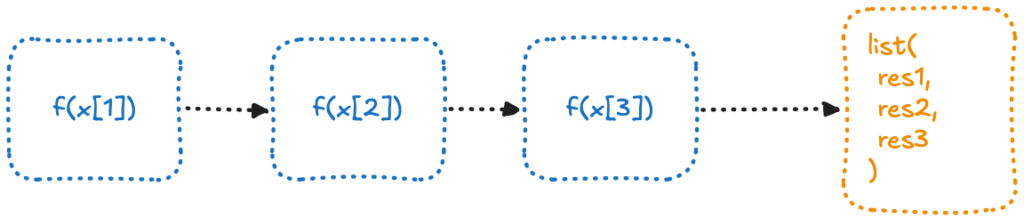
Ce type de problème est qualifié de « embarrassingly parallel« , c’est-à-dire qu’il peut être facilement divisé en tâches indépendantes nécessitant peu ou pas de coordination. C’est pourquoi cela fonctionne bien en mode parallèle : chaque tâche peut être exécutée en même temps, avec un minimum d’effort ou de surcharge.
En R, le traitement parallèle moderne s’effectue via {future}, , un package qui fournit un cadre unifié pour le calcul parallèle et distribué. Ce cadre est accompagné d’autres packages qui implémentent des fonctions basées dessus, comme {future.apply}, qui transforme la famille apply en traitement parallèle.
Voici comment nous pouvons adapter le code :
library(future)
library(future.apply)
plan(
strategy = multisession,
workers = 3
)
future_lapply(
c("1", 12, NA),
\(x){
# Mimicking some computational time
Sys.sleep(1)
sprintf("I'm %s", x)
}
)
Que se passe-t-il ici ?
- Nous avons configuré
{future}pour utiliser 3 sessions R différentes. Schématiquement,{future}ouvre et interagit avec 3 processus R différents sur votre machine. - Nous remplaçons
lapplyparfuture_lapply, ce qui signifie que chaque fonction\()sera exécutée dans une autre session, en même temps. - Ensuite, les résultats sont combinés dans une liste, nous donnant le même résultat qu’avant.
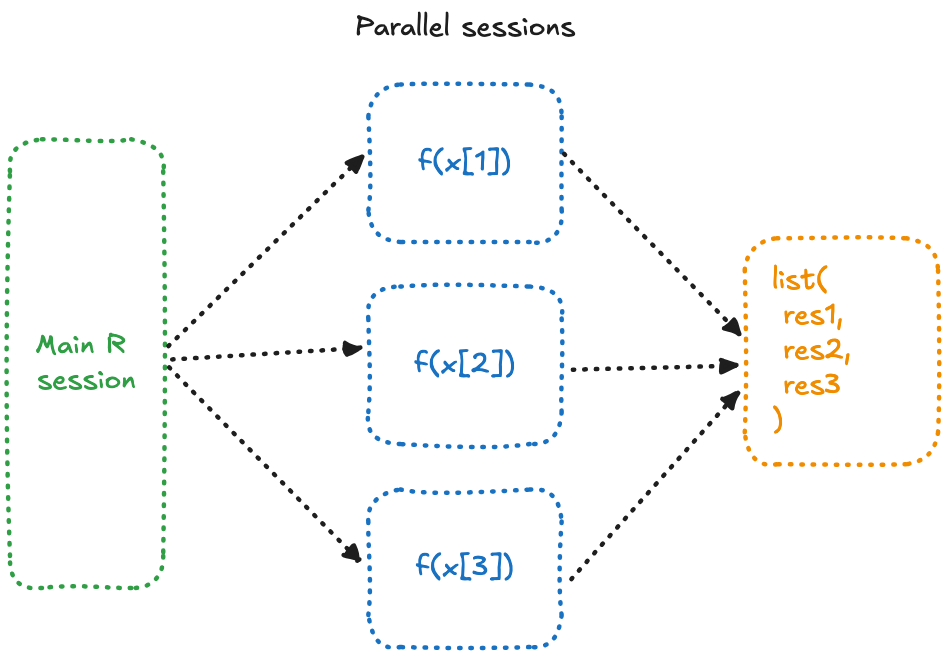
Alors, quelle est la différence ?
Avec la méthode standard lapply(), les \() sont exécutées une à une, ce qui signifie que chaque itération prend 1 seconde, et le processus entier dure 3 secondes.
En revanche, avec future_lapply(), chaque fonction \() est exécutée simultanément dans des sessions différentes, ce qui signifie que l’ensemble du calcul prend 1 seconde (ou un peu plus, car il faut tenir compte du transfert des objets entre les sessions et leur retour, mais ce n’est pas le point principal).
Comparons les durées d’exécution séquentielle et parallèle :
system.time({
lapply(
c("1", 12, NA),
\(x){
# Mimicking some computational time
Sys.sleep(1)
sprintf("I'm %s", x)
}
)
})
user system elapsed
0.001 0.001 3.017
system.time({
future_lapply(
c("1", 12, NA),
\(x){
# Mimicking some computational time
Sys.sleep(1)
sprintf("I'm %s", x)
}
)
})
user system elapsed
0.090 0.007 1.205
Le calcul parallèle peut être vu comme : « prends ceci, découpe-le en petits morceaux, envoie-les ailleurs, et j’attendrai que tu fasses quelque chose avec eux avant de me les rendre ».
Inconvénients du calcul parallèle
Plus de CPU/mémoire
Exécuter plusieurs sessions R consomme davantage de CPU et de mémoire, ce qui peut poser problème si votre matériel est limité. Cependant, comme le dit le proverbe : « Vous pouvez toujours acheter plus de matériel, mais vous ne pouvez pas acheter plus de temps. »
Le coût du transport
Bien que le traitement parallèle puisse accélérer des tâches longues, il faut tenir compte du coût de « transport ». Lorsqu’un calcul s’effectue dans une session R différente, R doit transférer les données et charger les packages nécessaires dans cette session. Le processus fonctionne ainsi :
- Analyse statique : R analyse le code pour déterminer quelles données et packages sont nécessaires.
- Transfert des données : Les données sont écrites sur le disque et rechargées dans la nouvelle session.
- Récupération des résultats : Les résultats des calculs sont écrits sur le disque et lus dans la session principale.
Ce surcoût peut parfois dépasser le coût du calcul lui-même. Un exemple concret :
big_m <- matrix(
sample(1:1e5, 1e5),
nrow = 10
)
diams <- purrr::map_df(
rep(
ggplot2::diamonds,
n = 100
),
identity
)
system.time({
lapply(
list(
diams,
big_m
),
\(x){
dim(x)
}
)
})
user system elapsed
0.001 0.000 0.000
system.time({
future_lapply(
list(
diams,
big_m
),
\(x){
dim(x)
}
)
})
user system elapsed
0.037 0.003 0.066
Pensez à cela comme ceci :
Si emballer un cadeau de Noël vous prend 20 secondes, et que vous avez trois cadeaux à emballer, vous pourriez envisager de déléguer la tâche. Cependant, imaginez passer 5 secondes à apporter les cadeaux à vos enfants, 10 secondes à leur expliquer comment les emballer (qu’ils mettront aussi 20 secondes à faire), puis 5 secondes à les ramener. Dans ce cas, le coût de la délégation dépasse les bénéfices, et il serait plus rapide de le faire vous-même !
NERD DIGRESSION ON: Vous vous demandez comment {future} analyse le code ? Grâce au package {globals} :
expr_to_be_run <- substitute({
lapply(
list(
# using shorter object for more
# redable output
matrix(1:2),
1:2
),
\(x){
dim(x)
}
)
})
globals::globalsOf(expr_to_be_run)
$`{`
.Primitive("{")
$lapply
function (X, FUN, ...)
{
FUN <- match.fun(FUN)
if (!is.vector(X) || is.object(X))
X <- as.list(X)
.Internal(lapply(X, FUN))
}
<bytecode: 0x14e913970>
<environment: namespace:base>
$list
function (...) .Primitive("list")
$matrix
function (data = NA, nrow = 1, ncol = 1, byrow = FALSE, dimnames = NULL)
{
if (is.object(data) || !is.atomic(data))
data <- as.vector(data)
.Internal(matrix(data, nrow, ncol, byrow, dimnames, missing(nrow),
missing(ncol)))
}
<bytecode: 0x14f283d28>
<environment: namespace:base>
$`:`
.Primitive(":")
$dim
function (x) .Primitive("dim")
attr(,"where")
attr(,"where")$`{`
<environment: base>
attr(,"where")$lapply
<environment: base>
attr(,"where")$list
<environment: base>
attr(,"where")$matrix
<environment: base>
attr(,"where")$`:`
<environment: base>
attr(,"where")$dim
<environment: base>
attr(,"class")
[1] "Globals" "list"
NERD DIGRESSION OFF.
Asynchrone
Explorons maintenant la programmation asynchrone, qui diffère fondamentalement du traitement parallèle.
La programmation asynchrone consiste également à « calculer ailleurs », mais la différence clé est que vous ne divisez pas une tâche en morceaux pour attendre les résultats. Au lieu de cela, l’état d’esprit asynchrone est : « Envoie cette tâche s’exécuter ailleurs, rends-moi immédiatement le contrôle, et je vérifierai plus tard si elle est terminée. »
C’est précisément ce que permet la fonction future():
# Reconfiguring
library(future)
plan(
strategy = multisession,
workers = 3
)
# Identifying current session ID
Sys.getpid()
[1] 23667
my_future <- future({
Sys.sleep(1)
Sys.getpid()
})
print("I immediately have my console")
"I immediately have my console" # Check if the future is resolved, i.e. if it has returned
resolved(my_future)
[1] FALSE
Sys.sleep(1)
resolved(my_future)
[1] TRUE
value(my_future)
[1] 41533
En essence, la programmation asynchrone consiste à envoyer un calcul à exécuter ailleurs, sans se préoccuper du moment exact où le résultat sera prêt. Cela contraste avec le calcul parallèle, où le timing est crucial car il faut récupérer et combiner les résultats de toutes les tâches.
Pour résumer :
- Le calcul parallèle est bloquant : vous attendez que tous les résultats soient prêts avant de continuer.
- La programmation asynchrone est non bloquante : vous poursuivez votre travail et revenez vérifier les résultats lorsqu’ils sont prêts.
Gérer les résultats asynchrones avec {promises}
Les workflows asynchrones posent deux défis principaux :
- 1. Suivi de l’achèvement des tâches : Comment savoir quand une tâche est terminée ?
On pourrait imaginer une solution comme celle-ci :
my_future <- future({ Sys.sleep(1) Sys.getpid() }) while(!resolved(my_future)){ Sys.sleep(0.1) } value(my_future)[1] 41533
Cependant, cette approche va à l’encontre de l’objectif principal de la programmation asynchrone : ne pas bloquer.
- 2. Gestion des résultats : Que faire lorsqu’une tâche est terminée, que ce soit un succès ou un échec ?
Un défi de la programmation asynchrone est qu’elle sépare le calcul de ce que vous faites avec le résultat. Vous envoyez une tâche pour qu’elle soit calculée ailleurs et, lorsqu’elle revient finalement, vous devez la gérer. Idéalement, il faudrait un moyen de définir à la fois la tâche asynchrone et la logique de réponse ensemble, de sorte que tout — ce qu’il faut calculer et comment traiter le résultat — soit écrit dans un endroit cohérent.
future() + promise()
C’est ici que {promise} entre en jeu. Inspiré par la manière dont JavaScript gère la programmation asynchrone (ou du moins comment cela se faisait auparavant), {promise} offre deux fonctionnalités clés :
- Il surveille activement (ou interroge) le future pour vérifier quand il est résolu.
- Il vous permet de définir des fonctions qui s’exécuteront une fois que le future sera terminé.
La structure par défaut ressemble à ceci
library(future)
library(promises)
fut <- future({
Sys.sleep(3)
1 + 1
})
then(fut,
onFulfilled = \(result) {
# What happens if the future resolved and returns
cli::cat_line("Yeay")
print(result)
},
onRejected = \(err) {
# What happens if the future
cli::cat_line("Ouch")
print(err)
}
)
finally(
fut,
\(){
cli::cat_line("Future resolved")
}
)
Ici, tout est regroupé en un seul endroit :
- Le code asynchrone.
- Ce qu’il faut faire lorsqu’il retourne une valeur.
- Ce qu’il faut faire en cas d’échec.
- Ce qu’il faut faire à chaque fois, que ce soit un succès ou un échec.
Si vous exécutez ce code dans votre console, vous récupérerez immédiatement le contrôle de celle-ci. Après 5 secondes, vous verrez la sortie lorsque la tâche sera terminée.
Pour rendre ce processus encore plus fluide, le package {promise} propose des wrappers permettant d’écrire ce code dans un format plus convivial avec des pipes :
library(magrittr)
future({
Sys.sleep(3)
1 + 1
}) %>%
then(\(result){
cli::cat_line("Yeay")
print(result)
}) %>%
catch(\(error){
cli::cat_line("Ouch")
print(err)
}) %>%
finally(\(){
cli::cat_line("Future resolved")
})
Ou, encore plus court :
library(magrittr)
future({
Sys.sleep(3)
1 + 1
}) %...>% (\(result){
cli::cat_line("Yeay")
print(result)
}) %...!% (\(error){
cli::cat_line("Ouch")
print(err)
}) %>%
finally(\(){
cli::cat_line("Future resolved")
})
Alors, quelle approche est la meilleure ? Cela dépend entièrement de vous.
Personnellement, je trouve la version entièrement basée sur les pipes plus concise et élégante. Cependant, la version avec des noms de fonctions explicites (then, catch, etc.) rend la logique plus facile à suivre et le code plus accessible pour les nouveaux développeurs. C’est un compromis entre brièveté et clarté.
Pourquoi ce long post ?
Async dans {shiny}
Si vous lisez encore, vous vous demandez peut-être : « D’accord, mais pourquoi est-ce important ? » Laissez-moi vous expliquer pourquoi cela compte si vous êtes un développeur {shiny}.
Par défaut, R est mono-thread, ce qui signifie qu’il ne peut traiter qu’une seule tâche à la fois. Cela est également vrai pour {shiny} : il traite une opération à la fois. Cela signifie que si l’Utilisateur A déclenche un calcul, l’action de l’Utilisateur B ne peut commencer qu’une fois que la tâche de l’Utilisateur A est terminée.
Dans la plupart des cas, ce n’est pas un problème : les calculs en R sont généralement rapides. Si l’Utilisateur B doit attendre 0,1 seconde que la tâche de l’Utilisateur A se termine, il ne s’en rendra probablement même pas compte.
Cependant, ce comportement devient problématique lorsque votre application implique des calculs lourds, comme le rendu d’un rapport RMarkdown basé sur les entrées de l’application. Même un petit document RMarkdown peut prendre quelques secondes à être généré, ce qui est trop long dans une application multi-utilisateurs.
Voici un exemple simple pour illustrer ce point :
library(shiny)
ui <- fluidPage(
actionButton(
inputId = "launch",
label = "Launch Computation"
),
textOutput("time"),
textOutput("rnorm")
)
server <- function(input, output, session) {
r <- reactiveValues()
output$time <- renderText({
invalidateLater(1000)
format(Sys.time(), "%H:%M:%S")
})
observeEvent(input$launch, {
Sys.sleep(3)
r$norm <- rnorm(10)
})
output$rnorm <- renderText({
r$norm
})
}
shinyApp(ui = ui, server = server)
Si vous ouvrez cette application dans deux onglets de navigateur distincts et que vous cliquez sur le bouton dans l’un des onglets, vous remarquerez que l’application se fige dans l’autre. Cela se produit parce que l’observeEvent bloque toute la session R pendant qu’elle traite la tâche.
Mais que se passerait-il si nous appliquions ce que nous avons appris précédemment avec {future} ? Essayons :
library(shiny)
library(future)
library(promises)
plan(
strategy = multisession,
workers = 3
)
ui <- fluidPage(
actionButton(
inputId = "launch",
label = "Launch Computation"
),
textOutput("time"),
textOutput("rnorm")
)
server <- function(input, output, session) {
r <- reactiveValues()
output$time <- renderText({
invalidateLater(1000)
format(Sys.time(), "%H:%M:%S")
})
observeEvent(input$launch, {
future({
Sys.sleep(10)
rnorm(10)
},
seed=TRUE
) %>%
then(\(result){
cli::cat_line("Yeay")
r$norm <- result
}) %>%
catch(\(error){
cli::cat_line("Ouch")
r$norm <- NULL
})
# Render has to return otherwise it blocks
return(NULL)
})
output$rnorm <- renderText({
r$norm
})
}
shinyApp(ui = ui, server = server)
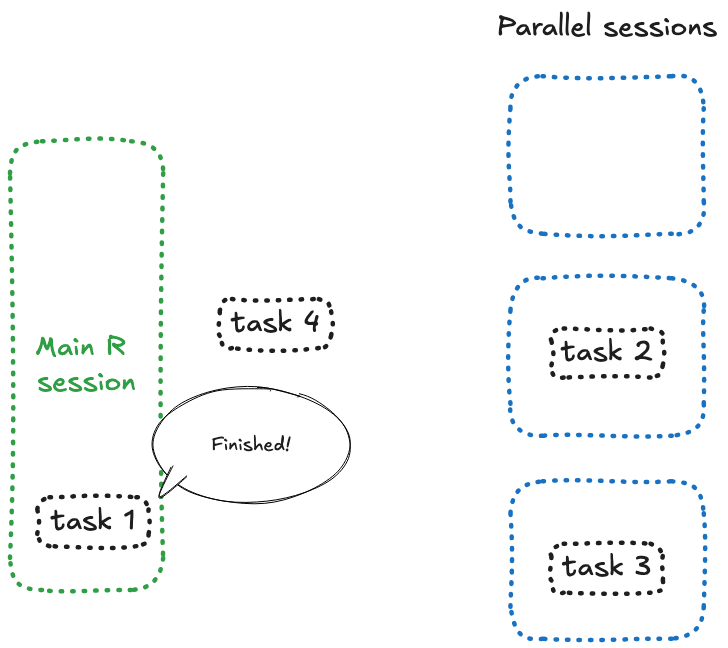
Ouvrons maintenant cette application dans trois onglets, puis cliquons sur le bouton. Tout fonctionne comme prévu. Maintenant, ouvrons un quatrième onglet et cliquons sur les quatre boutons l’un après l’autre. Eh oui, tout est bloqué maintenant.
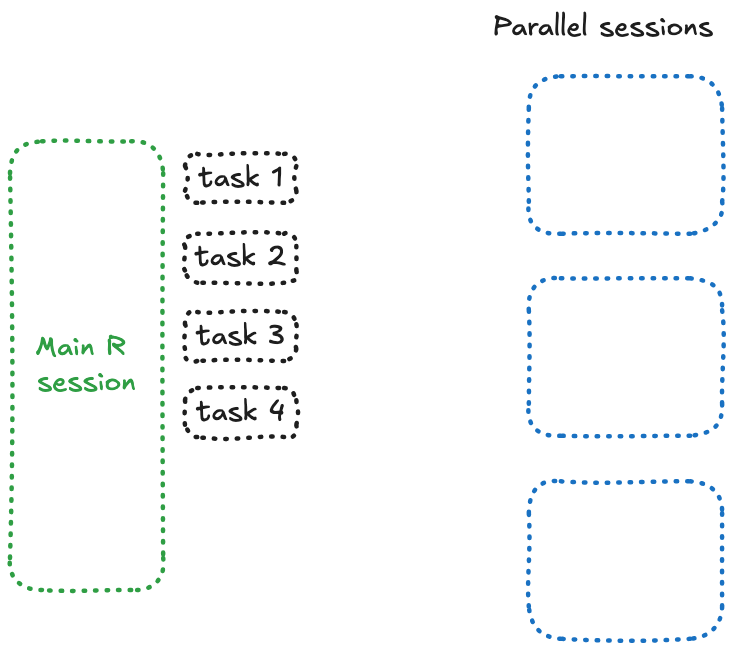
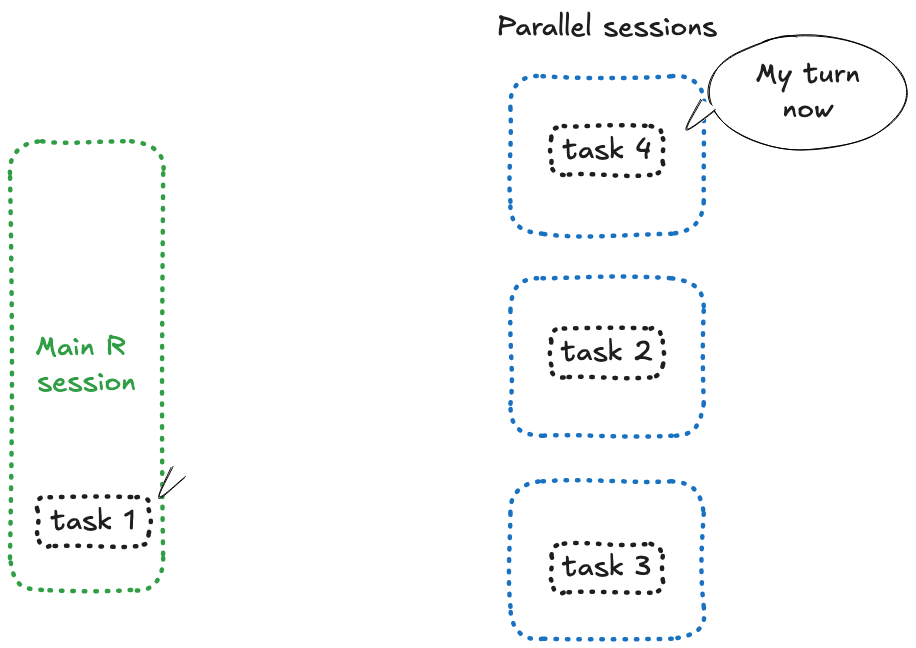
La raison est simple : quelque chose, quelque part, est bloqué — et si vous avez prêté attention au nombre, c’est parce que vous essayez d’envoyer 4 future à 3 sessions. Et voici ce qui se passe : lorsque {future} n’a plus de session libre, il bloque et attend.
C’est quelque chose que vous pouvez reproduire dans une simple session R :
library(future)
plan(
strategy = multisession,
workers = 3
)
a <- future({
Sys.sleep(4)
})
b <- future({
Sys.sleep(4)
})
c <- future({
Sys.sleep(4)
})
d <- future({
Sys.sleep(4)
})
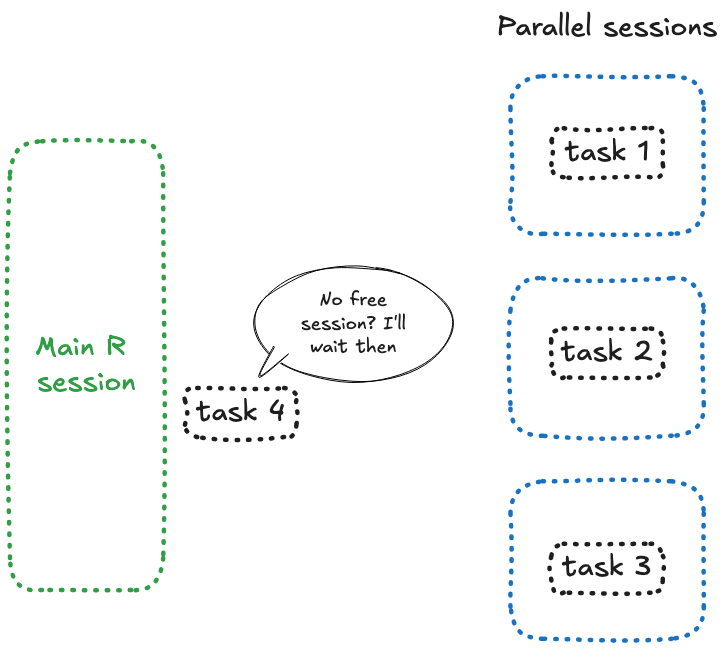
future_promise()
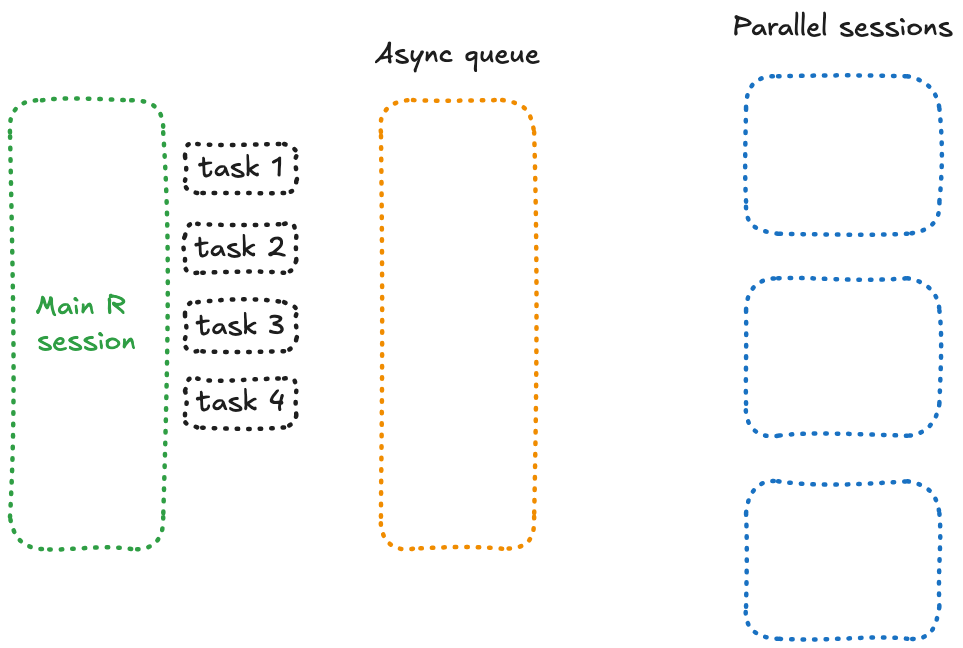
C’est là qu’entre en jeu future_promise(), un wrapper intelligent autour de future() et promise() qui permet d’éviter le problème de blocage rencontré précédemment.
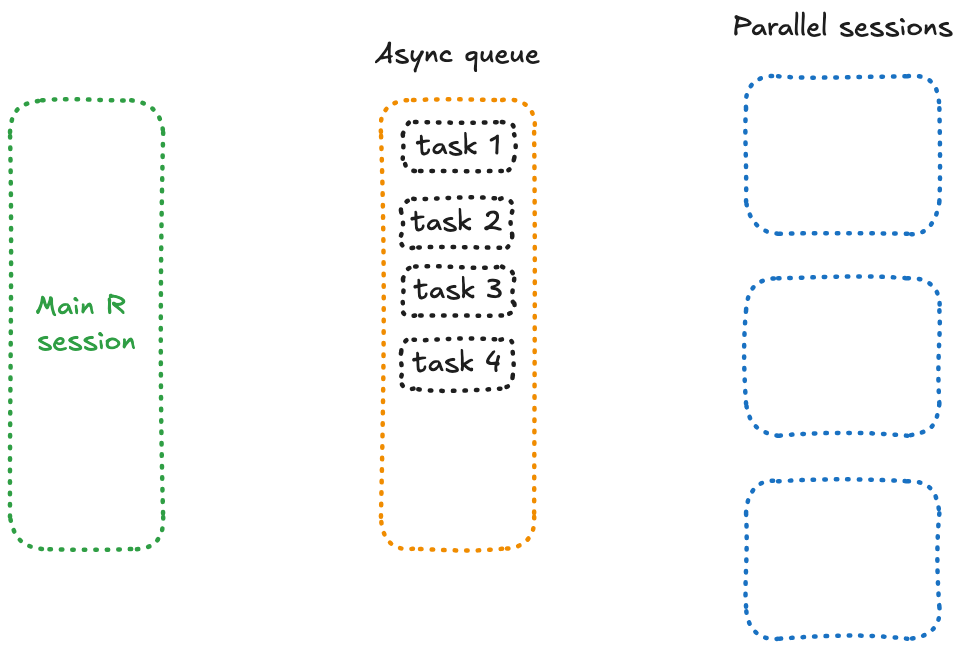
Ce qui distingue future_promise() ? Il crée une file d’attente asynchrone pour gérer tous les appels à future(). Au lieu de bloquer la session principale lorsque les workers sont occupés, il place les tâches en attente dans une file d’attente et les exécute dès qu’un worker devient disponible.
Conceptuellement, cela signifie que toutes vos tâches en attente se trouvent dans une session séparée, prêtes à être traitées dès qu’un worker libre peut s’en occuper — un fonctionnement qui ressemble à ceci :
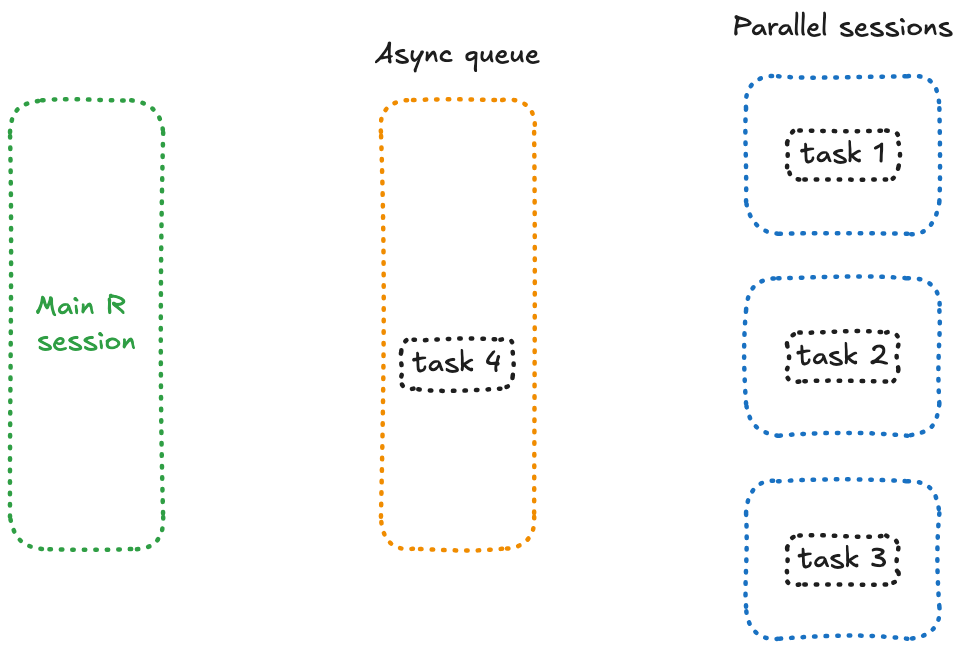
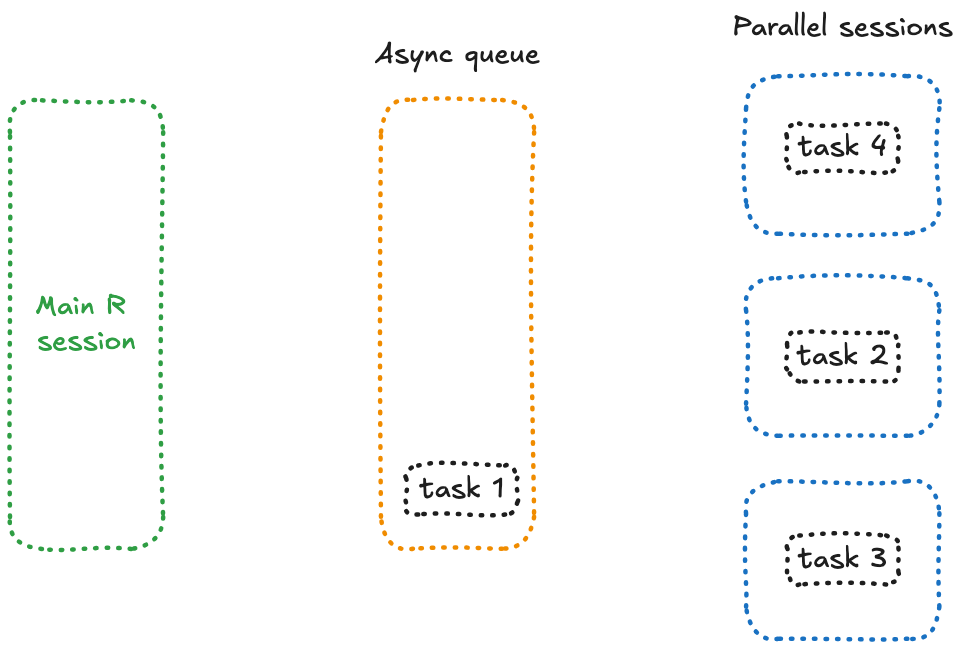
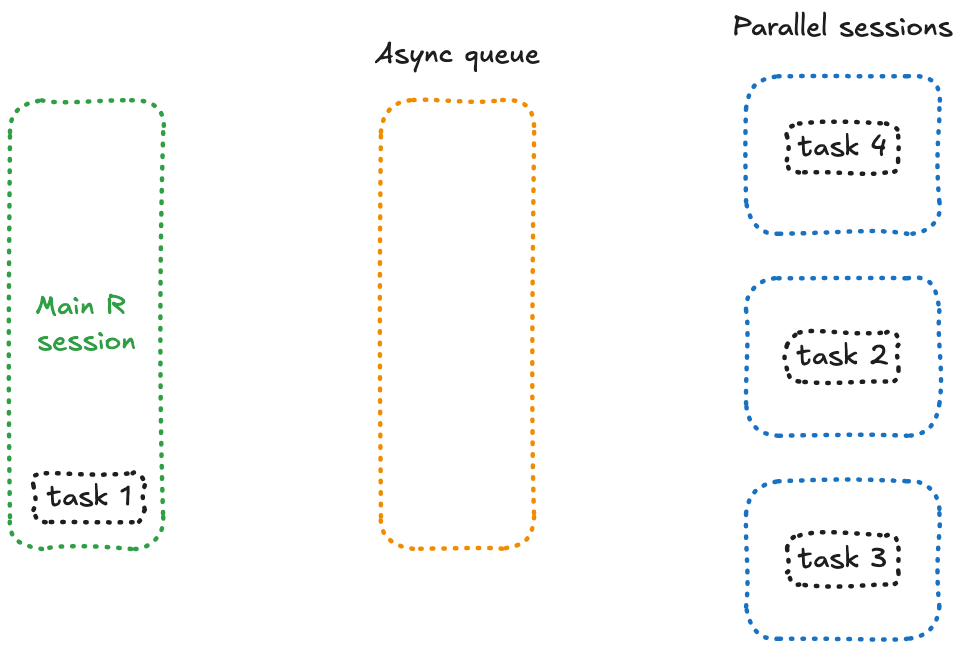
Mettons à jour notre code :
library(shiny)
library(future)
library(promises)
plan(
strategy = multisession,
workers = 3
)
ui <- fluidPage(
actionButton(
inputId = "launch",
label = "Launch Computation"
),
textOutput("time"),
textOutput("rnorm")
)
server <- function(input, output, session) {
r <- reactiveValues()
output$time <- renderText({
invalidateLater(1000)
format(Sys.time(), "%H:%M:%S")
})
observeEvent(input$launch, {
future_promise({
Sys.sleep(10)
rnorm(10)
},
seed=TRUE
) %>%
then(\(result){
cli::cat_line("Yeay")
r$norm <- result
}) %>%
catch(\(error){
cli::cat_line("Ouch")
r$norm <- NULL
})
# Render has to return otherwise it blocks
return(NULL)
})
output$rnorm <- renderText({
r$norm
})
}
shinyApp(ui = ui, server = server)
Yeay! Notre application fonctionne comme prévu 🎉.
Cependant, il y a une chose à garder à l’esprit : comme il s’agit d’une file d’attente, si vous envoyez 4 futures à 3 sessions, la 4ème tâche ne commencera qu’une fois que la 1ère tâche sera terminée (par exemple, après 10 secondes). Cela signifie que le temps d’attente total peut encore être significatif pour certaines tâches.
Et le petit dernier : shiny::ExtendedTask
Mettre en œuvre une solution avec future_promise() peut sembler un peu complexe. Heureusement, depuis la version 1.8.1, {shiny} inclut une prise en charge asynchrone native grâce à la classe R6 ExtendedTask. Cette classe offre un comportement réactif intégré pour gérer les tâches asynchrones de manière fluide.
Reprenons notre exemple précédent en utilisant
ExtendedTask:
library(shiny)
library(future)
library(promises)
plan(
strategy = multisession,
workers = 3
)
ui <- fluidPage(
actionButton(
inputId = "launch",
label = "Launch Computation"
),
textOutput("time"),
textOutput("rnorm")
)
server <- function(input, output, session) {
et_r_norm <- ExtendedTask$new(function() {
future_promise({
Sys.sleep(3)
rnorm(10)
}, seed = TRUE)
})
output$time <- renderText({
invalidateLater(1000)
format(Sys.time(), "%H:%M:%S")
})
observeEvent(input$launch, {
et_r_norm$invoke()
})
output$rnorm <- renderText({
et_r_norm$result()
})
}
shinyApp(ui = ui, server = server)
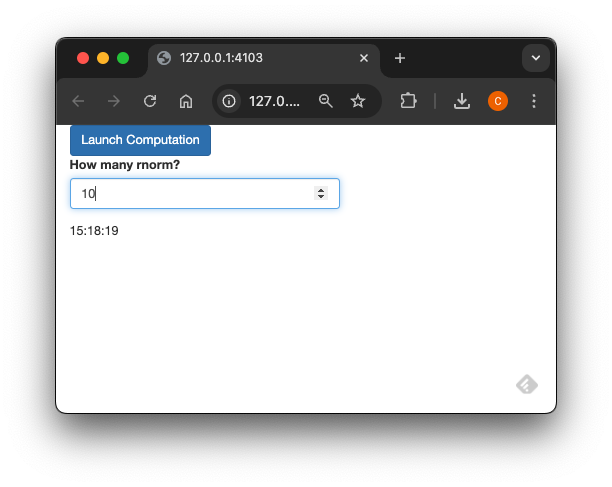
Bien sûr, ExtendedTask peut également prendre des entrées directement depuis l’application Shiny.
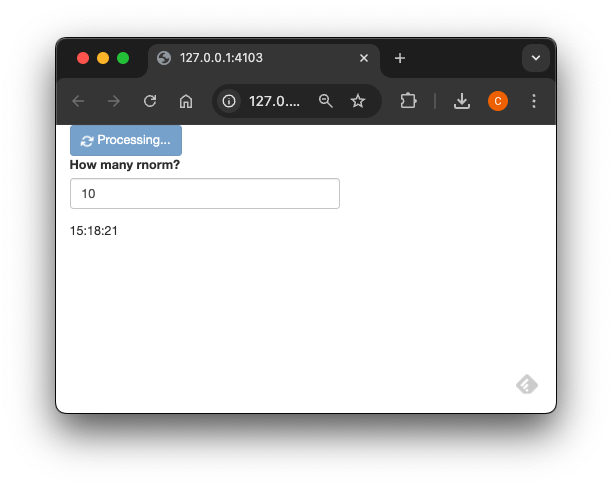
library(shiny)
library(future)
library(promises)
plan(
strategy = multisession,
workers = 3
)
ui <- fluidPage(
input_task_button(
id = "launch",
label = "Launch Computation"
),
numericInput(
"rnorm_size",
"How many rnorm?",
value = 10,
min = 1,
max = 10
),
textOutput("time"),
textOutput("rnorm")
)
server <- function(input, output, session) {
et_r_norm <- ExtendedTask$new(function(r_norm_n) {
future_promise({
Sys.sleep(3)
rnorm(r_norm_n)
}, seed = TRUE)
})
output$time <- renderText({
invalidateLater(1000)
format(Sys.time(), "%H:%M:%S")
})
observeEvent(input$launch, {
et_r_norm$invoke(input$rnorm_size)
})
output$rnorm <- renderText({
et_r_norm$result()
})
}
shinyApp(ui = ui, server = server)
library(shiny)
library(bslib)
library(future)
library(promises)
plan(
strategy = multisession,
workers = 3
)
ui <- fluidPage(
input_task_button(
id = "launch",
label = "Launch Computation"
),
numericInput(
"rnorm_size",
"How many rnorm?",
value = 10,
min = 1,
max = 10
),
textOutput("time"),
textOutput("rnorm")
)
server <- function(input, output, session) {
et_r_norm <- ExtendedTask$new(function(r_norm_n) {
future_promise({
Sys.sleep(3)
rnorm(r_norm_n)
}, seed = TRUE)
})|> bind_task_button("launch")
output$time <- renderText({
invalidateLater(1000)
format(Sys.time(), "%H:%M:%S")
})
observeEvent(input$launch, {
et_r_norm$invoke(input$rnorm_size)
})
output$rnorm <- renderText({
et_r_norm$result()
})
}
shinyApp(ui = ui, server = server)
Conclusions
Nous avons exploré comment la programmation parallèle et asynchrone représentent deux approches et états d’esprit distincts, bien qu’elles puissent être combinées — par exemple, une tâche asynchrone peut déclencher des calculs parallèles.
Maîtriser ces techniques peut considérablement améliorer l’expérience utilisateur de vos applications, en particulier lorsqu’il s’agit de gérer des tâches longues ou un trafic utilisateur élevé.
Toujours pas sûr de savoir comment implémenter ces concepts dans votre application ? Vous avez essayé, mais cela ne fonctionne pas comme prévu ? Discutons en !


