
Durant la rstudio::conf(2019L), j’ai présenté un poster intitulé « Building Big Shiny Apps – A Workflow ». Vous pouvez trouver ce poster ici, et ce billet de blog est une tentative de transcription de sa présentation à Austin.
Comme il s’agit d’un sujet assez long, j’ai divisé ce billet en deux parties : la première présentera le contexte et le pourquoi, et la seconde présentera un workflow étape par étape et les outils nécessaires.
Cet article est à la base de l’écriture de notre livre : https://engineering-shiny.org/. Vous y trouverez des informations complémentaires.
Motivation
Table des matières
L’idée derrière ce poster (et maintenant ce billet de blog) n’est pas de parler de la façon de déployer et de scaler, mais du processus de construction de l’application. Pourquoi ? Beaucoup de blogs et de livres parlent de la mise en production d’applications. Très peu parlent de la façon de travailler pendant la construction de ces applications. C’est pourquoi j’ai choisi de parler du processus, du workflow et des outils que nous utilisons chez ThinkR lors de la création d’applications Shiny.
Donc, pour résumer, nous ne parlerons pas de ce qu’il faut faire quand l’application est prête, nous parlerons de comment la rendre prête.
À propos de Shiny
Si vous lisez cette page, il y a de fortes chances que vous sachiez déjà ce qu’est une application Shiny – une application web qui communique avec R, construite en R, et qui fonctionne avec R. Presque tout le monde peut créer un prototype pour un produit data science, et ce en quelques heures seulement. Aucune connaissance en HTML, CSS ou JavaScript n’est requise, ce qui le rend vraiment facile à utiliser – vous pouvez rapidement créer un POC. Mais que faire maintenant que vous voulez construire une grosse application Shiny ?

Qu’est-ce qu’une « grosse » application Shiny ?
- Eh bien, tout d’abord, une qui comprend plusieurs milliers de lignes de code (R et autres).
- C’est aussi une application qui est potentiellement développée par plusieurs codeurs, travaillant sur la même application en même temps.
- C’est une application où la mise à l’échelle est importante.
- La maintenabilité et la facilité de mise à jour sont importantes.
- Dans de nombreux cas, les Shiny Apps en production ne sont pas utilisées par des personnes à l’aise avec R.
- Les gens se fient à cette application pour prendre des décisions dans le monde réel, avec des conséquences réelles – tout comme Joe Cheng l’a exprimé dans sa définition de ce que signifie « en production » :
👌 Great definition of what "in production" means:
— Colin 🤘🌱🏃♀️ (@_ColinFay) January 17, 2019
🗣 "Software environments that are used and relied on by real users with real consequences if things go wrong"
Construire une grosse application Shiny — les challenges
Trouver une bonne interface utilisateur
Choisir une interface utilisateur est difficile – nous avons naturellement tendance, en tant que codeurs, à nous concentrer sur le backend, c’est-à-dire la partie algorithmique de l’application. Mais soyons clairs : quelle que soit la complexité et l’innovation de votre backend, si votre interface utilisateur est mauvaise, votre application est mauvaise. C’est la triste vérité. Si les gens ne comprennent pas comment utiliser votre application, votre application ne fonctionne pas. Peu importe à quel point le backend est incroyable.
Essayez de trouver une interface simple et efficace. Un outil que les gens peuvent comprendre et utiliser en quelques secondes. N’implémentez pas de fonctionnalités ou d’éléments visuels qui ne sont pas réellement nécessaires, juste « au cas où ». Et passez du temps à travailler sur cette interface utilisateur, en pensant vraiment aux éléments visuels que vous implémentez.
Travailler en équipe
Une grosse Shiny Apps signifie généralement que plusieurs personnes travailleront sur l’application. Par exemple, chez ThinkR, 3 à 4 personnes travaillent habituellement sur une application. Alors, comment on organise ça ?
Du point de vue des outils:
- Utiliser un outil de versioning (je ne suis pas sûr de devoir m’étendre sur ce sujet 😉 ) )
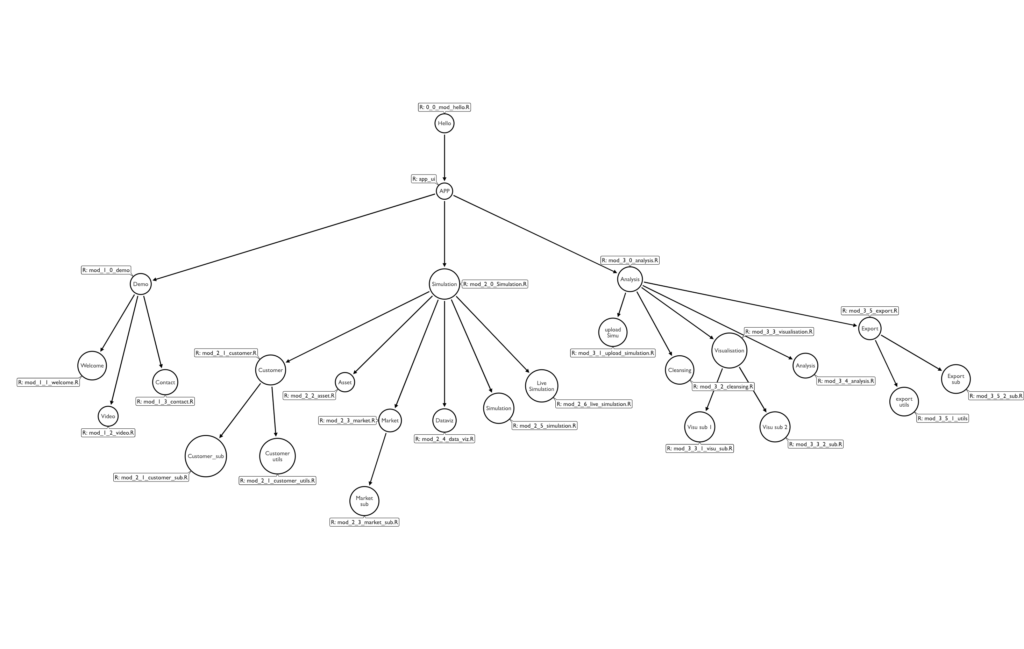
- Pensez à votre application comme à un arbre, et divisez-la autant que possible en petits morceaux. Ensuite, créez un module Shiny module par morceaux. Cela vous permet de diviser le travail, et aussi d’avoir des fichiers plus petits – il est plus facile de travailler sur 20 fichiers de 200 lignes que sur un gros fichier app.R.
Ici, par exemple, la division d’une app en modules et sous-modules :
Du point de vue organisation
- Définir une personne chargée d’avoir une vue d’ensemble de l’application. Cette personne lancera le projet, et écrira le squelette de l’application, avec la bonne structure des modules et des fichiers. Cette personne sera également chargée d’accepter les nouvelles merge requests d’autres développeurs, et d’orchestrer les branches master et dev.
- Énumérez les tâches et ouvrez une issue pour chaque tâche sur votre système de versionning. Chaque problème sera résolu dans une branche distincte.
- Enfin, assignez un module à un développeur – s’il semble que travailler sur un module est un travail à deux personnes, divisez-le à nouveau en deux autres sous-modules. Il s’agit d’une tâche relativement complexe, car la sortie d’un module influence l’entrée d’un autre, alors assurez-vous de bien les affecter.
Rendre l’application prod-ready
Cela implique deux choses : la mise à l’échelle et la maintenance. Comme dit au départ de cet article, je ne vais pas m’étendre sur le sujet de la mise à l’échelle, comme beaucoup ont déjà écrit à ce sujet, mais voici un conseil : faites en sorte que le processus R exécutant l’application fasse le moins possible, et en particulier éviter lui de faire ce qu’il n’est pas censé faire. Ce qui inclut : utiliser JavaScript pour que le navigateur client calcul des choses (au lieu de faire R faire le travail — don’t worry, le JS de base est facile à apprendre 😉 ), utiliser la parallélisation et l’asynchrone, et si possible, faites le gros du travail à l’extérieur de la session R qui exécute l’application.
La maintenance, d’autre part, est une chose à laquelle il faut penser dès le début. Il s’agit notamment de s’assurer que l’application fonctionnera sur le long terme et que les nouvelles fonctionnalités pourront être facilement implémentées.
- Travailler sur le long terme : séparer le code avec la « logique métier » (c’est-à-dire la manipulation des données et l’algorithme, qui peut fonctionner en dehors du contexte de l’application) du code qui fait tourner l’application. De cette façon, vous pouvez écrire des tests de régression pour ces fonctions afin de vous assurer qu’elles sont stables.
- Implémenter de nouveaux éléments : comme nous travaillons avec des modules, il est facile d’insérer de nouveaux éléments dans l’application globale.
C’est tout pour aujourd’hui !
La deuxième partie de ce post qui décrit le flux de travail en détails, et parle des outils à utiliser : https://rtask.thinkr.fr/fr/vers-un-workflow-pour-des-applications-shiny-prod-ready-2-2/


