
During the
As this is a rather long topic, I’ve divided this post into two parts: this first post will talk about the background and motivation, and the second post will present a step by step workflow and the necessary tools.
This post is at the premise of our book: https://engineering-shiny.org/. You will find all complementary information in it.
Motivation
Table of Contents
The idea behind this poster (and now this blog post) is not to talk about how to deploy and scale, but about the process of building the app. Why? A lot of blog posts and books talk about putting apps in production. Very few talks about working on building these apps. This is why I’ve chosen to talk about the process, workflow, and tools we use at ThinkR when building big Shiny Apps.
So,we’ll not talk about what to do when the app is ready, we’ll talk about how to make it ready.
About Big Shiny Apps
If you’re reading this page, chances are you already know what a Shiny App is — a web application that communicates with R, built in R, and working with R. With Shiny, almost anybody can create a prototype for a small data product in a matter of hours. And no knowledge of HTML, CSS or JavaScript is required, making it really easy to use as you can rapidly create a POC.
But what to do now that you want to build a big Shiny App?

What’s a big Shiny App?
- Well, first, one that includes several thousand lines of code (R and others).
- It’s also one that is potentially developed by several coders, working on the same application at the same time.
- It’s an application where scaling matters.
- Maintainability and ease of upgrading are important.
- In many cases, Shiny Apps in production are not used by “tech literate” users.
- People rely on this application for making real-world decisions, with real consequences — just as phrased by Joe Cheng with his definition of what “in production” means:
👌 Great definition of what "in production" means:
— Colin 🤘🌱🏃♀️ (@_ColinFay) January 17, 2019
🗣 "Software environments that are used and relied on by real users with real consequences if things go wrong"
Building a Big Shiny App, the Challenges
Finding a good UI (and stick with it)
Choosing a UI is hard — we have a natural tendency, as coders, to be focused on the backend, i.e the algorithmic part of the application. But let’s state the truth: no matter how complex and innovative your backend is, your application is bad if your UI is bad. That’s the hard truth. If people can’t understand how to use your application, your application doesn’t work. No matter how incredible the backend is.
So try to find a simple and efficient UI (I’m personally a big fan of minimalist UI). One that people can understand and use in a matter of seconds. Don’t implement features or visual elements that are not actually needed, just “in case”. And spend time working on that UI, really thinking about what visual elements you are implementing.
This part is a crucial part, as it will influence the rest of the work — a big app means numerous features, and it can be hard to find a way to organize all these features in an understandable, easy to use user interface.
Working as a team
Big Shiny Apps usually means that several peoples will work on the application. For example, at
From the tools point of view:
- Use version control (not sure I have to expand on that topic 😉 )
- Think of your shiny app as a tree, and divide it as much as possible into little pieces. Then, create one Shiny module by piece. This allows you to split the work, and also to have smaller files — it’s easier to work on 40 files of 200 lines than on one big app.R file.
Here is, for example, the division of an app into modules and sub modules:
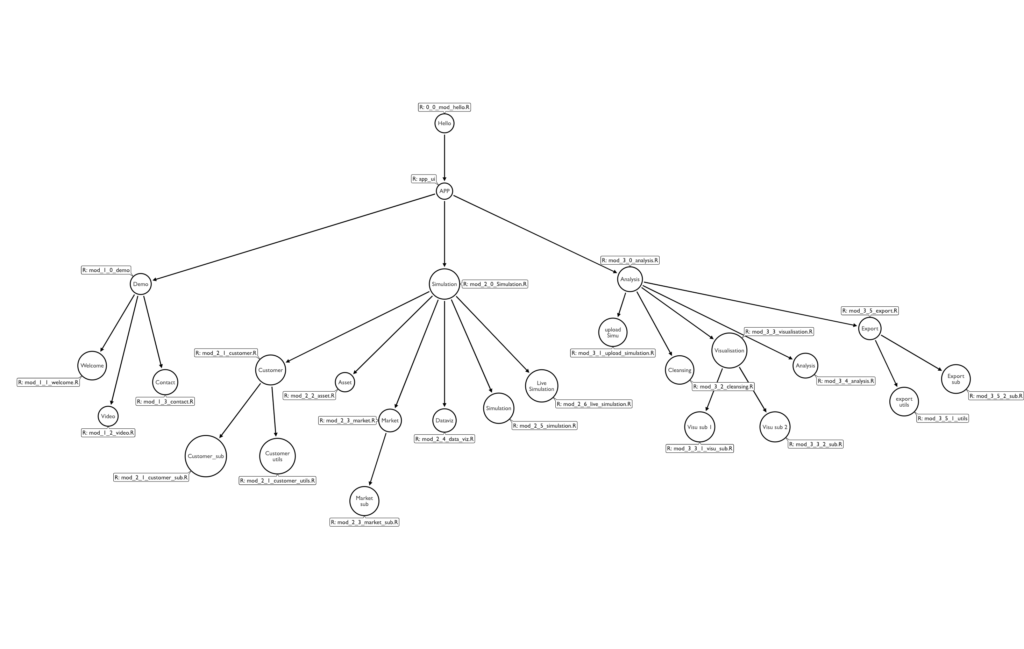
From the organizational point of view
- Define one person who is in charge of having the big picture. This person will kick off the project, and write the skeleton of the app, with the good modules and files structure. This person will also be in charge of accepting new merge requests from other developers, and to orchestrate the master and dev branches.
- List the tasks, and open one issue for each task on your version control system. Each issue will be solved in a separate branch.
- Finally, assign one module to one developer — if it seems that working on one module is a two-person job, divide again into two other submodules. This is a relatively complex task, as the output of one module influences the input of another, so be sure to assign them well. This division into modules allow working simultaneously on the same app without interfering with other people’s code — as each developer is working on their own modules, collaboration is
way simpler.
Making the app production ready
his includes two things: scaling and maintaining. As said in the disclaimer, I won’t expand on the topic of scaling, as many have written about that, but here is one piece of advice: make the R process running the app do as little as possible, and in particular prevent it from doing what it’s not supposed to do. Which includes: use JavaScript so that the client browser renders things (instead of making R do the work — basic JS is easy to learn), use parallelization and async, and if possible, make the heavy lifting be done outside the R session running the app.
Maintenance, on the other, is something to think about from the beginning. It includes being able to ensure that the application will work
- Working in the long run: separate the code with “business logic” (aka the data manipulation and the algorithm, that can work outside the context of the app) from the code building the application. That way, you can write regression tests for these functions to ensure they are stable.
- Implement new elements: as we are working with modules, it’s easy to insert new elements inside the global application.
That’s it for today!
The second part of this post describes the workflow in details, and talk about the tools to use : https://rtask.thinkr.fr/building-big-shiny-apps-a-workflow-2/


